L1-L2 Communication (Portals)
In Aztec, what we call portals are the key element in facilitating communication between L1 and L2. While typical L2 solutions rely on synchronous communication with L1, Aztec's privacy-first nature means this is not possible. You can learn more about why in the previous section.
Traditional L1 <-> L2 communication might involve direct calls between L2 and L1 contracts. However, in Aztec, due to the privacy components and the way transactions are processed (kernel proofs built on historical data), direct calls between L1 and L2 would not be possible if we want to maintain privacy.
Portals are the solution to this problem, acting as bridges for communication between the two layers. These portals can transmit messages from public functions in L1 to private functions in L2 and vice versa, thus enabling messaging while maintaining privacy.
This page covers:
- How portals enable privacy communication between L1 and L2
- How messages are sent, received, and processed
- Message Boxes and how they work
- How and why linking of contracts between L1 and L2 occurs
Objective
The goal is to set up a minimal-complexity mechanism, that will allow a base-layer (L1) and the Aztec Network (L2) to communicate arbitrary messages such that:
- L2 functions can
callL1 functions. - L1 functions can
callL2 functions. - The rollup-block size have a limited impact by the messages and their size.
High Level Overview
This document will contain communication abstractions that we use to support interaction between private functions, public functions and Layer 1 portal contracts.
Fundamental restrictions for Aztec:
- L1 and L2 have very different execution environments, stuff that is cheap on L1 is most often expensive on L2 and vice versa. As an example,
keccak256is cheap on L1, but very expensive on L2. - Private function calls are fully "prepared" and proven by the user, which provides the kernel proof along with commitments and nullifiers to the sequencer.
- Public functions altering public state (updatable storage) must be executed at the current "head" of the chain, which only the sequencer can ensure, so these must be executed separately to the private functions.
- Private and public functions within Aztec are therefore ordered such that first private functions are executed, and then public. For a more detailed description of why, see above.
- Messages are consumables, and can only be consumed by the recipient. See Message Boxes for more information.
With the aforementioned restrictions taken into account, cross-chain messages can be operated in a similar manner to when public functions must transmit information to private functions. In such a scenario, a "message" is created and conveyed to the recipient for future use. It is worth noting that any call made between different domains (private, public, cross-chain) is unilateral in nature. In other words, the caller is unaware of the outcome of the initiated call until told when some later rollup is executed (if at all). This can be regarded as message passing, providing us with a consistent mental model across all domains, which is convenient.
As an illustration, suppose a private function adds a cross-chain call. In such a case, the private function would not have knowledge of the result of the cross-chain call within the same rollup (since it has yet to be executed).
Similarly to the ordering of private and public functions, we can also reap the benefits of intentionally ordering messages between L1 and L2. When a message is sent from L1 to L2, it has been "emitted" by an action in the past (an L1 interaction), allowing us to add it to the list of consumables at the "beginning" of the block execution. This practical approach means that a message could be consumed in the same block it is included. In a sophisticated setup, rollup could send an L2 to L1 message that is then consumed on L1, and the response is added already in . However, messages going from L2 to L1 will be added as they are emitted.
Because everything is unilateral and async, the application developer have to explicitly handle failure cases such that user can gracefully recover. Example where recovering is of utmost importance is token bridges, where it is very inconvenient if the locking of funds on one domain occur, but never the minting or unlocking on the other.
Components
Portal
A "portal" refers to the part of an application residing on L1, which is associated with a particular L2 address (the confidential part of the application). It could be a contract or even an EOA on L1.
Message Boxes
In a logical sense, a Message Box functions as a one-way message passing mechanism with two ends, one residing on each side of the divide, i.e., one component on L1 and another on L2. Essentially, these boxes are utilized to transmit messages between L1 and L2 via the rollup contract. The boxes can be envisaged as multi-sets that enable the same message to be inserted numerous times, a feature that is necessary to accommodate scenarios where, for instance, "deposit 10 eth to A" is required multiple times. The diagram below provides a detailed illustration of how one can perceive a message box in a logical context.
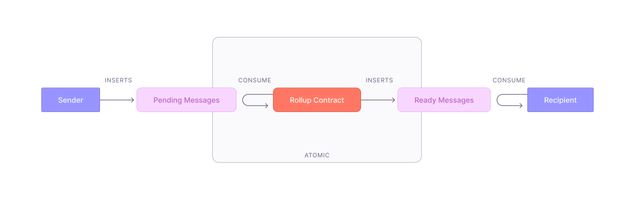
- Here, a
senderwill insert a message into thependingset, the specific constraints of the actions depend on the implementation domain, but for now, say that anyone can insert into the pending set. - At some point, a rollup will be executed, in this step messages are "moved" from pending on Domain A, to ready on Domain B. Note that consuming the message is "pulling & deleting" (or nullifying). The action is atomic, so a message that is consumed from the pending set MUST be added to the ready set, or the state transition should fail. A further constraint on moving messages along the way, is that only messages where the
senderandrecipientpair exists in a leaf in the contracts tree are allowed! - When the message has been added to the ready set, the
recipientcan consume the message as part of a function call.
A difference when compared to other cross-chain setups, is that Aztec is "pulling" messages, and that the message doesn't need to be calldata for a function call. For other rollups, execution is happening FROM the "message bridge", which then calls the L1 contract. For Aztec, you call the L1 contract, and it should then consume messages from the message box.
Why? Privacy! When pushing, we would be needing full calldata. Which for functions with private inputs is not really something we want as that calldata for L1 -> L2 transactions are committed to on L1, e.g., publicly sharing the inputs to a private function.
By instead pulling, we can have the "message" be something that is derived from the arguments instead. This way, a private function to perform second half of a deposit, leaks the "value" deposited and "who" made the deposit (as this is done on L1), but the new owner can be hidden on L2.
To support messages in both directions we require two of these message boxes (one in each direction). However, due to the limitations of each domain, the message box for sending messages into the rollup and sending messages out are not fully symmetrical. In reality, the setup looks closer to the following:
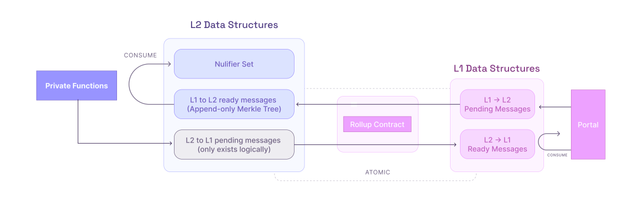
The L2 -> L1 pending messages set only exist logically, as it is practically unnecessary. For anything to happen to the L2 state (e.g., update the pending messages), the state will be updated on L1, meaning that we could just as well insert the messages directly into the ready set.
Rollup Contract
The rollup contract has a few very important responsibilities. The contract must keep track of the L2 rollup state root, perform state transitions and ensure that the data is available for anyone else to synchronize to the current state.
To ensure that state transitions are performed correctly, the contract will derive public inputs for the rollup circuit based on the input data, and then use a verifier contract to validate that inputs correctly transition the current state to the next. All data needed for the public inputs to the circuit must be from the rollup block, ensuring that the block is available. For a valid proof, the rollup state root is updated and it will emit an event to make it easy for anyone to find the data.
As part of state transitions where cross-chain messages are included, the contract must "move" messages along the way, e.g., from "pending" to "ready".
Kernel Circuit
For L2 to L1 messages, the public inputs of a user-proof will contain a dynamic array of messages to be added, of size at most MAX_MESSAGESTACK_DEPTH, limited to ensure it is not impossible to include the transaction. The circuit must ensure, that all messages have a sender/recipient pair, and that those pairs exist in the contracts tree and that the sender is the L2 contract that actually emitted the message.
For consuming L1 to L2 messages the circuit must create proper nullifiers.
Rollup Circuit
The rollup circuit must ensure that, provided two states and and the rollup block , applying to using the transition function must give us , e.g., . If this is not the case, the constraints are not satisfied.
For the sake of cross-chain messages, this means inserting and nullifying L1 L2 in the trees, and publish L2 L1 messages on chain. These messages should only be inserted if the sender and recipient match an entry in the contracts leaf (as checked by the kernel).
Messages
While a message could theoretically be arbitrarily long, we want to limit the cost of the insertion on L1 as much as possible. Therefore, we allow the users to send 32 bytes of "content" between L1 and L2. If 32 suffices, no packing required. If the 32 is too "small" for the message directly, the sender should simply pass along a sha256(content) instead of the content directly (note that this hash should fit in a field element which is ~254 bits. More info on this below). The content can then either be emitted as an event on L2 or kept by the sender, who should then be the only entity that can "unpack" the message.
In this manner, there is some way to "unpack" the content on the receiving domain.
The message that is passed along, require the sender/recipient pair to be communicated as well (we need to know who should receive the message and be able to check). By having the pending messages be a contract on L1, we can ensure that the sender = msg.sender and let only content and recipient be provided by the caller. Summing up, we can use the structs seen below, and only store the commitment (sha256(LxToLyMsg)) on chain or in the trees, this way, we need only update a single storage slot per message.
struct L1Actor {
address: actor,
uint256: chainId,
}
struct L2Actor {
bytes32: actor,
uint256: version,
}
struct L1ToL2Msg {
L1Actor: sender,
L2Actor: recipient,
bytes32: content,
bytes32: secretHash,
}
struct L2ToL1Msg {
L2Actor: sender,
L1Actor: recipient,
bytes32: content,
}
The bytes32 elements for content and secretHash hold values that must fit in a field element (~ 254 bits).
The nullifier computation should include the index of the message in the message tree to ensure that it is possible to send duplicate messages (e.g., 2 x deposit of 500 dai to the same account).
To make it possible to hide when a specific message is consumed, the L1ToL2Msg is extended with a secretHash field, where the secretPreimage is used as part of the nullifier computation. This way, it is not possible for someone just seeing the L1ToL2Msg on L1 to know when it is consumed on L2.
Combined Architecture
The following diagram shows the overall architecture, combining the earlier sections.
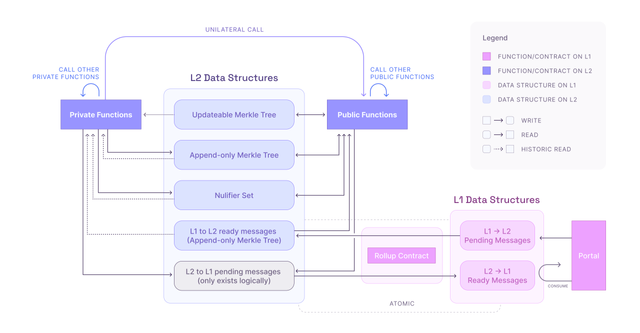
Learn more
Check out the protocol specs for more information about cross-chain communication and contracts on L1.